
Here is the idea, with CLIP image retrieval works as follows. We embed the images we have using a CLIP model and store it somewhere like in a vector database. And then, during inference we can use a query image or a prompt, embed that and find the closest images from the stored embeddings that can be retrieved. The problem is when, the embedded images have too many objects or some objects are in the background and we still want our system to retrieve them. This is because CLIP embeds the image as a whole. Think of it like what a word embedding model is to a sentence embedding model. We want to be able to search for words which are equivalent to objects in an image. So the solution is to decompose the image into different objects using a object detection model and embed these decomposed images as well but link them to their parent image. This will allow us to retrieve the crops and also get the parent that the crop originated from. Let’s see how it works.
Install the Dependencies and import them
!pip install -q ultralytics torch matplotlib numpy pillow zipfile36 transformers
from ultralytics import YOLO
import matplotlib.pyplot as plt
from PIL import pillow
import os
from Zipfile import Zipfile, BadZipFile
import torch
from transformers import CLIPProcessor, CLIPModel, CLIPVisionModelWithProjection, CLIPTextModelWithProjectionDownload the COCO Dataset and unzip
!wget http://images.cocodataset.org/zips/val2017.zip -O coco_val2017.zip
def extract_zip_file(extract_path):
try:
with ZipFile(extract_path+".zip") as zfile:
zfile.extractall(extract_path)
# remove zipfile
zfileTOremove=f"{extract_path}"+".zip"
if os.path.isfile(zfileTOremove):
os.remove(zfileTOremove)
else:
print("Error: %s file not found" % zfileTOremove)
except BadZipFile as e:
print("Error:", e)
extract_val_path = "./coco_val2017"
extract_zip_file(extract_val_path)We can then take some of the images and create a list of examples.
source = ['coco_val2017/val2017/000000000139.jpg', '/content/coco_val2017/val2017/000000000632.jpg', '/content/coco_val2017/val2017/000000000776.jpg', '/content/coco_val2017/val2017/000000001503.jpg', '/content/coco_val2017/val2017/000000001353.jpg', '/content/coco_val2017/val2017/000000003661.jpg']Initiate the YOLO model and the CLIP Model
In this example we are going to use the latest Ultralytics Yolo10x model along with OpenAI clip-vit-base-patch32 .
device = "cuda"
# YOLO Model
model = YOLO('yolov10x.pt')
# Clip model
model_id = "openai/clip-vit-base-patch32"
image_model = CLIPVisionModelWithProjection.from_pretrained(model_id, device_map = device)
text_model = CLIPTextModelWithProjection.from_pretrained(model_id, device_map = device)
processor = CLIPProcessor.from_pretrained(model_id)Running the detection model
results = model(source=source, device = "cuda")Let’s show us results with this code snippet
# Visualize the results
fig, ax = plt.subplots(2, 3, figsize=(15, 10))
for i, r in enumerate(results):
# Plot results image
im_bgr = r.plot() # BGR-order numpy array
im_rgb = Image.fromarray(im_bgr[..., ::-1]) # RGB-order PIL image
ax[i%2, i//2].imshow(im_rgb)
ax[i%2, i//2].set_title(f"Image {i+1}")
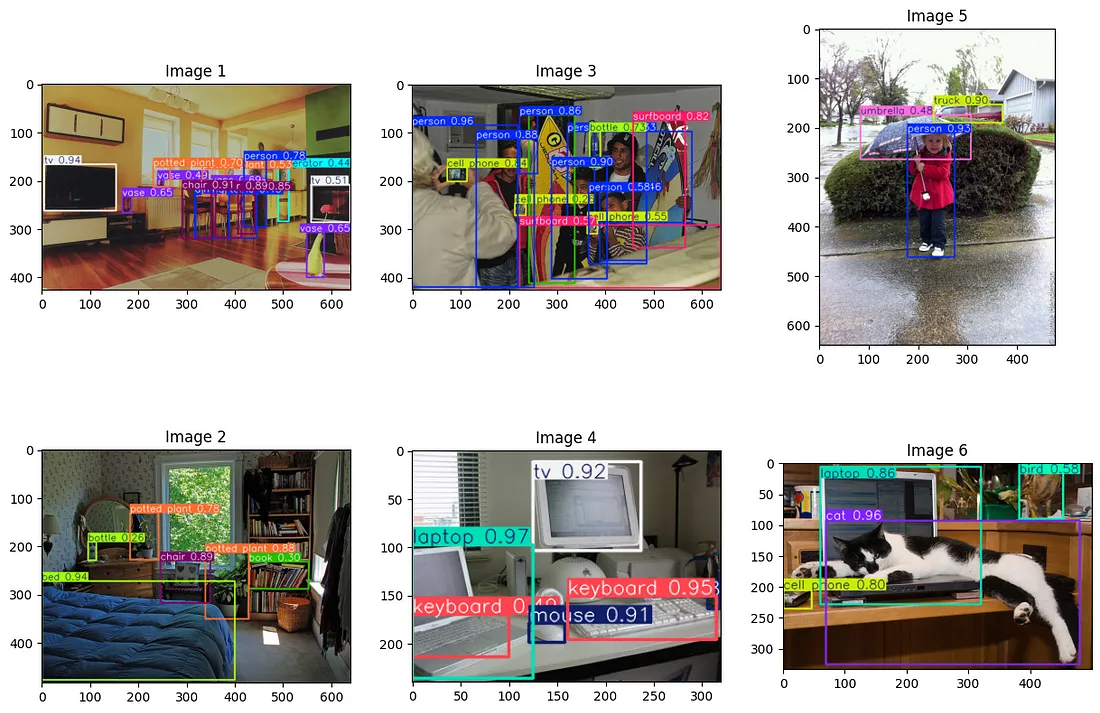
So we can see that the YOLO model works quite well in detecting the objects in the images. It does make some mistakes where it has tagged the monitor as TV. But that is fine. The actual classes that YOLO assigns are not that essential because we are going to use CLIP to do the inference.
Defining some helper Classes
class CroppedImage:
def __init__(self, parent, box, cls):
self.parent = parent
self.box = box
self.cls = cls
def display(self, ax = None):
im_rgb = Image.open(self.parent)
cropped_image = im_rgb.crop(self.box)
if ax is not None:
ax.imshow(cropped_image)
ax.set_title(self.cls)
else:
plt.figure(figsize=(10, 10))
plt.imshow(cropped_image)
plt.title(self.cls)
plt.show()
def get_cropped_image(self):
im_rgb = Image.open(self.parent)
cropped_image = im_rgb.crop(self.box)
return cropped_image
def __str__(self):
return f"CroppedImage(parent={self.parent}, boxes={self.box}, cls={self.cls})"
def __repr__(self):
return self.__str__()
class YOLOImage:
def __init__(self, image_path, cropped_images):
self.image_path = str(image_path)
self.cropped_images = cropped_images
def get_image(self):
return Image.open(self.image_path)
def get_caption(self):
cls =[]
for cropped_image in self.cropped_images:
cls.append(cropped_image.cls)
unique_cls = set(cls)
count_cls = {cls: cls.count(cls) for cls in unique_cls}
count_string = " ".join(f"{count} {cls}," for cls, count in count_cls.items())
return "this image contains " + count_string
def __str__(self):
return self.__repr__()
def __repr__(self):
cls =[]
for cropped_image in self.cropped_images:
cls.append(cropped_image.cls)
return f"YOLOImage(image={self.image_path}, cropped_images={cls})"
class ImageEmbedding:
def __init__(self, image_path, embedding, cropped_image = None):
self.image_path = image_path
self.cropped_image = cropped_image
self.embedding = embedding
CroppedImage Class
The CroppedImage class represents a portion of an image cropped from a larger parent image. It is initialized with the path to the parent image, the bounding box defining the crop area, and a class label (e.g., “cat” or “dog”). This class includes methods to display the cropped image and to retrieve it as an image object. The display method allows for visualizing the cropped portion either on a provided axis or by creating a new figure, making it versatile for different use cases. Additionally, __str__ and __repr__ methods are implemented for easy and informative string representation of the object.
YOLOImage Class
The YOLOImage class is designed to handle images processed with the YOLO object detection model. It takes the path to the original image and a list of CroppedImage instances that represent the detected objects within the image. The class provides methods to open and display the full image and to generate a caption summarizing the objects detected in the image. The caption method aggregates and counts the unique class labels from the cropped images, providing a concise description of the image contents. This class is particularly useful for managing and interpreting results from object detection tasks.
ImageEmbedding Class
The ImageEmbedding class has an image and its associated embedding, which is a numerical representation of the image’s features. This class can be initialized with the path to the image, the embedding vector, and optionally a CroppedImage instance if the embedding corresponds to a specific cropped portion of the image. The ImageEmbedding class is essential for tasks involving image similarity, classification, and retrieval, as it provides a structured way to store and access the image data alongside its computed features. This integration facilitates efficient image processing and machine learning workflows.
Crop each image and create a list of YOLOImage Objects
yolo_images: list[YOLOImage]= []
names= model.names
for i, r in enumerate(results):
crops:list[CroppedImage] = []
boxes = r.boxes
classes = r.boxes.cls
for j, box in enumerate(r.boxes):
box = tuple(box.xyxy.flatten().cpu().numpy())
cropped_image = CroppedImage(parent = r.path, box = box, cls = names[classes[j].int().item()])
crops.append(cropped_image)
yolo_images.append(YOLOImage(image_path=r.path, cropped_images=crops))Embed Images using CLIP
image_embeddings = []
for image in yolo_images:
input = processor.image_processor(images= image.get_image(), return_tensors = 'pt')
input.to(device)
embeddings = image_model(pixel_values = input.pixel_values).image_embeds
embeddings = embeddings/embeddings.norm(p=2, dim = -1, keepdim = True) # Normalize the embeddings
image_embedding = ImageEmbedding(image_path = image.image_path, embedding = embeddings)
image_embeddings.append(image_embedding)
for cropped_image in image.cropped_images:
input = processor.image_processor(images= cropped_image.get_cropped_image(), return_tensors = 'pt')
input.to(device)
embeddings = image_model(pixel_values = input.pixel_values).image_embeds
embeddings = embeddings/embeddings.norm(p=2, dim = -1, keepdim = True) # Normalize the embeddings
image_embedding = ImageEmbedding(image_path = image.image_path, embedding = embeddings, cropped_image = cropped_image)
image_embeddings.append(image_embedding)
**image_embeddings_tensor = torch.stack([image_embedding.embedding for image_embedding in image_embeddings]).squeeze()**We can now take these image embeddings and store in a vector database if we want to. But in this example we will just use the inner dot product technique to check the similarity and retrieve the images.
Retrieval
query = "image of a flowerpot"
text_embedding = processor.tokenizer(query, return_tensors="pt").to(device)
text_embedding = text_model(**text_embedding).text_embeds
similarities = (torch.matmul(text_embedding, image_embeddings_tensor.T)).flatten().detach().cpu().numpy()
# get the top 5 similar images
k = 5
top_k_indices = similarities.argsort()[-k:]
# Display the top 5 results
fig, ax = plt.subplots(2, 5, figsize=(20, 5))
for i, index in enumerate(top_k_indices):
if image_embeddings[index].cropped_image is not None:
image_embeddings[index].cropped_image.display(ax = ax[0][i])
else:
ax[0][i].imshow(Image.open(image_embeddings[index].image_path))
ax[1][i].imshow(Image.open(image_embeddings[index].image_path))
ax[0][i].axis('off')
ax[1][i].axis('off')
ax[1][i].set_title("Original Image")
plt.show()



You can see that we are able to retrieve even small plants which are hidden away in the background. Also sometimes it pulls the original image as the result because we are also embedding that .
This can be a very powerful technique. You can also finetune both the models for detection and embedding for your own images and improve the performance even more.
One downside is that we have to run the CLIP model on all the objects detected. One way to mitigate this is by limiting the number of boxes that YOLO produces.
You can check out the code on Colab at this link.
![]()
my website: http://www.akshaymakes.com/
linkedin: https://www.linkedin.com/in/akshay-ballal/
twitter: https://twitter.com/akshayballal95/